R并行方法简述
基于R包的并行方法

Table of Contents
1、简介
R语言提供了多种并行计算的方法,可以显著提高计算密集型任务的执行速度。本文章只简单介绍几种常用的并行计算方法,并提供示例代码,最后对比几种方法。
2、parallel包
parallel包是R中最基本和广泛使用的并行计算包。它是R基础安装的一部分,无需额外安装。
2.1 mclapply
mclapply 函数适用于类 Unix 系统(Mac 、Linux等),使用 fork 机制创建子进程。
library(parallel)
# 创建一个耗时的函数
time_consuming_function <- function(x) {
Sys.sleep(1) # 模拟耗时操作
return(x^2)
}
# 设置核心数
num_cores <- detectCores() - 1
# 使用 mclapply
system.time({
result <- mclapply(1:10, time_consuming_function, mc.cores = num_cores)
})
优点:
- 简单易用,语法类似于
lapply - 在 Unix-like 系统上效率高
缺点:
- 不支持 Windows 系统
- 不适合需要共享大量数据的任务
2.2 parLapply
parLapply 函数适用于所有操作系统,包括 Windows。
# 创建集群
cl <- makeCluster(num_cores)
# 使用 parLapply
system.time({
result <- parLapply(cl, 1:10, time_consuming_function)
})
# 停止集群
stopCluster(cl)
优点:
- 跨平台兼容(包括 Windows)
- 适合需要在节点间共享大量数据的任务
缺点:
- 相比
mclapply,设置稍微复杂 - 在某些情况下可能比
mclapply慢
3、foreach包与doParallel包
foreach包提供了一个更直观的并行循环接口。doParallel包为foreach提供了一个并行后端。二者经常同时使用达到并行的目的。
library(foreach)
library(doParallel)
# 注册并行后端
registerDoParallel(cores = num_cores)
# 使用 foreach
system.time({
result <- foreach(i = 1:10, .combine = c) %dopar% {
time_consuming_function(i)
}
})
# 停止并行后端
stopImplicitCluster()
优点:
- 语法直观,类似于常规的 for 循环
- 灵活,可以轻松组合结果
- 与多种并行后端兼容
缺点:
- 需要额外安装包
- 对于简单任务可能有些过于复杂
4、future包
future包提供了一个统一的并行和分布式处理框架,设计理念先进。
library(future)
library(future.apply)
# 设置并行策略
plan(multisession, workers = num_cores)
# 使用 future_lapply
system.time({
result <- future_lapply(1:10, time_consuming_function)
})
优点:
- 提供统一的接口for并行和序列化计算
- 非常灵活,支持多种并行策略
- 可以轻松切换不同的并行后端
缺点:
- 学习曲线可能较陡
- 对于简单任务可能显得过于复杂
5 、furrr包
furrr包结合了purrr的函数式编程和future的并行能力。
library(furrr)
# 设置并行策略
plan(multisession, workers = num_cores)
# 使用 future_map
system.time({
result <- future_map(1:10, time_consuming_function)
})
优点:
- 与
tidyverse生态系统完美集成 - 语法简洁,易于使用
- 保持了
purrr的一致性
缺点:
- 需要熟悉
purrr和函数式编程 - 对于不使用
tidyverse的项目可能不是最佳选择
6、RcppParallel包
RcppParallel包提供了C++级别的并行计算能力。当然,C++本身已经足够快,如果会C++推荐直接写C++。
library(Rcpp)
library(RcppParallel)
# 定义 C++ 函数
cppFunction(depends = "RcppParallel", code = '
#include <RcppParallel.h>
using namespace RcppParallel;
struct SquareWorker : public Worker {
const RVector<double> input;
RVector<double> output;
SquareWorker(const NumericVector input, NumericVector output)
: input(input), output(output) {}
void operator()(std::size_t begin, std::size_t end) {
std::transform(input.begin() + begin, input.begin() + end,
output.begin() + begin,
[](double x) { return x * x; });
}
};
// [[Rcpp::export]]
NumericVector parallelSquare(NumericVector x) {
NumericVector output(x.size());
SquareWorker worker(x, output);
parallelFor(0, x.size(), worker);
return output;
}
')
# 使用 C++ 并行函数
large_vector <- runif(1e7)
system.time({
result <- parallelSquare(large_vector)
})
优点:
- 性能极高,特别适合计算密集型任务
- 可以充分利用多核 CPU
缺点:
- 需要
C++编程知识 - 开发和调试可能较为复杂
7 、GPU 加速
对于特定类型的计算,可以使用 GPU 加速。例如,使用gpuR包:
library(gpuR)
# 创建 GPU 矩阵
A <- gpuMatrix(rnorm(1000*1000), nrow=1000, ncol=1000)
B <- gpuMatrix(rnorm(1000*1000), nrow=1000, ncol=1000)
# GPU 矩阵乘法
system.time({
C <- A %*% B
})
优点:
- 对于某些类型的计算(如矩阵运算)性能极高
- 可以处理大规模数据
缺点:
- 需要特定的硬件(GPU)
- 编程模型与 CPU 不同,可能需要学习新的技能
- 不是所有类型的计算都适合 GPU
8 、性能比较
下面比较了为了比较不同方法的性能,我们可以使用一个统一的测试函数:
# 安装必要的包(如果尚未安装)
if (!requireNamespace("parallel", quietly = TRUE)) install.packages("parallel")
if (!requireNamespace("foreach", quietly = TRUE)) install.packages("foreach")
if (!requireNamespace("doParallel", quietly = TRUE)) install.packages("doParallel")
if (!requireNamespace("future", quietly = TRUE)) install.packages("future")
if (!requireNamespace("future.apply", quietly = TRUE)) install.packages("future.apply")
if (!requireNamespace("furrr", quietly = TRUE)) install.packages("furrr")
if (!requireNamespace("microbenchmark", quietly = TRUE)) install.packages("microbenchmark")
if (!requireNamespace("ggplot2", quietly = TRUE)) install.packages("ggplot2")
# 加载必要的库
library(parallel)
library(foreach)
library(doParallel)
library(future)
library(future.apply)
library(furrr)
library(microbenchmark)
library(ggplot2)
# 设置随机种子以确保结果可重现
set.seed(123)
# 创建一个计算密集型函数
intensive_function <- function(x) {
result <- sum(sapply(1:1e5, function(i) sin(x * i)))
return(result)
}
# 创建测试数据
test_data <- runif(100, 0, 1)
# 设置核心数,减少到一个较小的值以避免连接限制
num_cores <- min(detectCores() - 1, 20) # 使用最多20个核心
# 定义测试函数
run_test <- function() {
# 1. 串行计算(基准)
serial <- lapply(test_data, intensive_function)
# 2. mclapply
mc <- mclapply(test_data, intensive_function, mc.cores = num_cores)
# 3. parLapply
cl <- makeCluster(num_cores)
par <- parLapply(cl, test_data, intensive_function)
stopCluster(cl)
# 4. foreach
cl <- makeCluster(num_cores)
registerDoParallel(cl)
foreach <- foreach(x = test_data, .combine = c) %dopar% {
intensive_function(x)
}
stopCluster(cl)
# 5. future.apply
plan(multisession, workers = num_cores)
future <- future_lapply(test_data, intensive_function)
# 6. furrr
plan(multisession, workers = num_cores)
furrr <- future_map(test_data, intensive_function)
# 检查结果是否一致
all_equal <- all(sapply(list(serial, mc, par, foreach, future, furrr), function(x) all.equal(x, serial)))
if (!all_equal) {
warning("警告:并非所有结果都相同")
}
}
# 运行性能测试
benchmark <- microbenchmark(
Serial = lapply(test_data, intensive_function),
mclapply = mclapply(test_data, intensive_function, mc.cores = num_cores),
parLapply = {
cl <- makeCluster(num_cores)
on.exit(stopCluster(cl))
parLapply(cl, test_data, intensive_function)
},
foreach = {
cl <- makeCluster(num_cores)
on.exit(stopCluster(cl))
registerDoParallel(cl)
foreach(x = test_data, .combine = c) %dopar% intensive_function(x)
},
future.apply = {
plan(multisession, workers = num_cores)
future_lapply(test_data, intensive_function)
},
furrr = {
plan(multisession, workers = num_cores)
future_map(test_data, intensive_function)
},
times = 10
)
# 打印结果
print(benchmark)
# 绘制性能比较图
p <- autoplot(benchmark) +
ggtitle("R并行计算包性能比较") +
theme_minimal()
# 保存结果
png("parallel_performance_comparison.png", width = 800, height = 600)
print(p)
dev.off()
# 输出结果摘要
result_summary <- summary(benchmark)
write.csv(result_summary, "parallel_performance_summary.csv")
cat("性能测试完成。结果已保存为图片和CSV文件。\n")
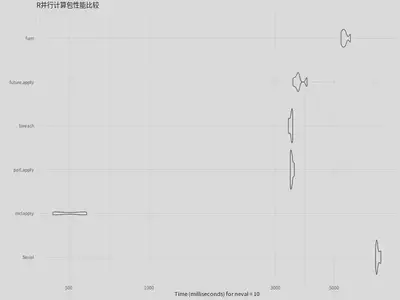
| expr | min | lq | mean | median | uq | max | neval |
|---|---|---|---|---|---|---|---|
| Serial | 7159.18 | 7208.81 | 7288.79 | 7239.40 | 7372.14 | 7495.29 | 10 |
| mclapply | 435.23 | 440.91 | 507.09 | 511.28 | 571.28 | 582.68 | 10 |
| parLapply | 3414.19 | 3423.42 | 3458.23 | 3451.61 | 3473.22 | 3535.35 | 10 |
| foreach | 3358.31 | 3396.43 | 3438.25 | 3453.85 | 3476.20 | 3487.60 | 10 |
| future.apply | 3495.26 | 3582.65 | 3678.58 | 3653.03 | 3684.38 | 3949.47 | 10 |
| furrr | 5304.65 | 5368.64 | 5486.57 | 5459.82 | 5530.38 | 5756.27 | 10 |
第一列是不同的并行计算方法,其他列分别表示最小值(min)、下四分位数(lq)、平均值(mean)、中位数(median)、上四分位数(uq)、最大值(max)和评估次数(neval)。所有时间单位都是毫秒。
9 、结论
选择合适的并行方法取决于多个因素,包括任务的性质、数据规模、可用的硬件资源等。一般来说:
- 对于简单的并行任务,
mclapply在类 Unix 系统上是最直接的选择。 - 对于需要跨平台兼容性的任务,
parLapply或foreach是好选择。 - 对于更复杂的并行策略,
future包提供了很大的灵活性。 - 对于与
tidyverse生态系统集成,furrr包是理想的选择。 - 对于计算密集型任务,考虑使用
RcppParallel或 GPU 加速。
建议在实际应用中进行基准测试,以确定最适合特定问题的并行方法。
对于统计方向的科研,据我个人的浅薄的经验,mclappy是最适合的,尤其是目前的服务器很多都是Linux 系统,在服务器上使用mclappy对一般的统计研究问题的代码运行会有一个很大的提升。